Want to remove AWS Glacier Vault? It can be tricky
Deleting an AWS Glacier vault is not as simple as pressing a “delete” button. Glacier, being an archival storage service, is designed with specific mechanisms to ensure data integrity and protection, but these features come with some challenges. I encountered this issue after purchasing a Synology NAS 923+ and enabling AWS Glacier as a backup solution (which I do not recommend). The backup process is painfully slow—it took nearly a week to upload 1TB of data—and if you ever want to delete a vault, you must first remove all its files (known as archives) before the vault itself can be deleted. Unfortunately, there’s no way to do this directly through the AWS web UI, leaving you to rely on the AWS CLI and API.
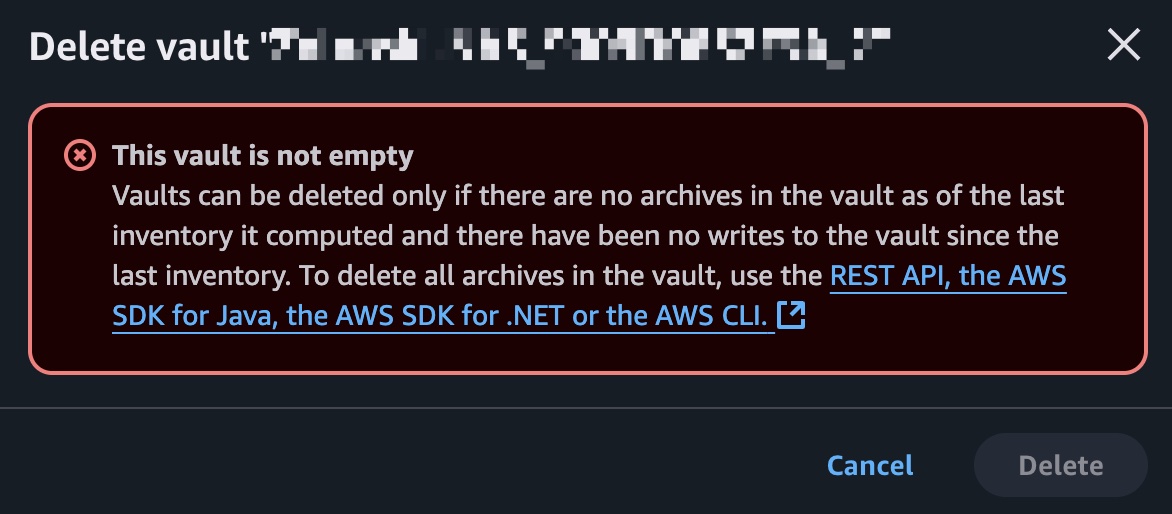
To make matters worse, AWS Glacier is not cheap. You pay for every API call, including uploading and deleting files. When I backed up 2TB of data, my first monthly AWS bill was around $25, which is far from economical for a personal backup solution. If you’re considering AWS Glacier for backups, these limitations and costs are important to keep in mind.
Why Is This a Challenge?
- No Direct UI Option: The AWS Management Console doesn’t offer a way to list or delete archives within a Glacier vault.
- API-Based Solution Required: You need to interact with the Glacier API to retrieve an inventory of the archives and delete them individually before deleting the vault.
- Time-Consuming Process: Retrieving the inventory can take hours, as it’s an asynchronous process.
Prerequisites
-
AWS CLI Installed
Ensure you have the AWS Command Line Interface (CLI) installed and configured with the necessary permissions.- Installation: Download and install the AWS CLI from the official documentation.
- Configuration: Run
aws configureto set up your credentials and default settings. You’ll need:- AWS Access Key ID
- AWS Secret Access Key
- Default Region (e.g.,
us-east-1) - Output format (optional, e.g.,
json)
- Verify the installation by running:
aws --version
-
jq Installed
Installjq, a lightweight and flexible JSON processor, to parse and manipulate inventory data. You can find installation instructions on the jq official website. Below are platform-specific steps:-
Linux:
sudo apt-get install jq -
macOS:
brew install jq -
Windows:
Download the.exebinary from the jq releases page and add it to your system’s PATH. -
Verify the installation by running:
jq --version
-
The Script
Below is a customizable script to handle the deletion process. I started by creating a new file in VS Code and named it delete.sh. After saving the script, I used the chmod command to change its permissions and make it executable:
chmod +x delete.shdelete.sh script:
#!/bin/bash
# AWS Account ID
ACCOUNT_ID="YOUR_ACCOUNT_ID"
# Vault Names (Add your vault names here)
VAULTS=("YOUR_VAULT_NAME", "VAULT 2")
# Dependency check function
check_dependency() {
if ! command -v "$1" &> /dev/null; then
echo "Error: $1 is not installed. Please install it to proceed."
exit 1
fi
}
# Check for required dependencies
check_dependency jq
check_dependency aws
# Iterate over each vault
for VAULT in "${VAULTS[@]}"; do
echo "Processing vault: $VAULT"
# Initiate inventory retrieval
echo "Initiating inventory retrieval for $VAULT..."
JOB_ID=$(aws glacier initiate-job \
--vault-name "$VAULT" \
--account-id "$ACCOUNT_ID" \
--job-parameters '{"Type": "inventory-retrieval"}' \
--query 'jobId' --output text)
if [ -z "$JOB_ID" ]; then
echo "Error: Failed to initiate inventory retrieval for $VAULT."
continue
fi
echo "Inventory retrieval initiated. Job ID: $JOB_ID"
# Wait for job completion
echo "Waiting for inventory retrieval to complete (this can take hours)..."
STATUS="InProgress"
while [ "$STATUS" == "InProgress" ]; do
STATUS=$(aws glacier describe-job \
--vault-name "$VAULT" \
--account-id "$ACCOUNT_ID" \
--job-id "$JOB_ID" \
--query 'StatusCode' --output text)
echo "Job status: $STATUS"
if [ "$STATUS" == "InProgress" ]; then
sleep 600 # Check every 10 minutes
fi
done
if [ "$STATUS" != "Succeeded" ]; then
echo "Error: Inventory retrieval failed for $VAULT. Status: $STATUS"
continue
fi
# Retrieve inventory
echo "Retrieving inventory for $VAULT..."
aws glacier get-job-output \
--vault-name "$VAULT" \
--account-id "$ACCOUNT_ID" \
--job-id "$JOB_ID" \
inventory_$VAULT.json
if [ ! -f inventory_$VAULT.json ]; then
echo "Error: Inventory file not found for $VAULT."
continue
fi
# Delete each archive in the vault
echo "Deleting archives in vault: $VAULT..."
ARCHIVE_IDS=$(jq -r '.ArchiveList[].ArchiveId' inventory_$VAULT.json)
TOTAL_ARCHIVES=$(echo "$ARCHIVE_IDS" | wc -w)
CURRENT=0
for ARCHIVE_ID in $ARCHIVE_IDS; do
((CURRENT++))
echo "Deleting archive: $ARCHIVE_ID in vault: $VAULT... ($CURRENT/$TOTAL_ARCHIVES)"
if ! aws glacier delete-archive \
--vault-name "$VAULT" \
--account-id "$ACCOUNT_ID" \
--archive-id "$ARCHIVE_ID"; then
echo "Error: Failed to delete archive $ARCHIVE_ID."
continue
fi
done
# Delete the vault
echo "Deleting vault: $VAULT..."
if ! aws glacier delete-vault \
--vault-name "$VAULT" \
--account-id "$ACCOUNT_ID"; then
echo "Error: Failed to delete vault $VAULT. Ensure it is empty and not recently modified."
continue
fi
echo "Vault $VAULT deleted successfully!"
doneIn Action

How It Works
- Initiate Inventory Retrieval: The script starts by initiating an inventory retrieval job for each specified vault.
- Wait for Job Completion: It continuously checks the status of the job, which can take hours to complete.
- Retrieve Inventory: Once the job succeeds, the script fetches the inventory and saves it as a JSON file.
- Delete Archives: Using the inventory, it iterates through each archive ID and deletes them one by one.
- Delete the Vault: Finally, it attempts to delete the empty vault.
Customization
- Replace
YOUR_ACCOUNT_IDwith your AWS account ID. - Replace
YOUR_VAULT_NAMEwith the names of your Glacier vaults.
Important Notes
- Permissions: Ensure your AWS IAM user or role has permissions for
glacier:InitiateJob,glacier:DescribeJob,glacier:GetJobOutput,glacier:DeleteArchive, andglacier:DeleteVault. - Costs: Inventory retrieval and archive deletions may incur charges depending on your Glacier plan.
- Time: Looping through and deleting 1.3TB of files took about 4 days straight for the script to run. No kidding.
Feel free to reach out if you have any questions, good luck!